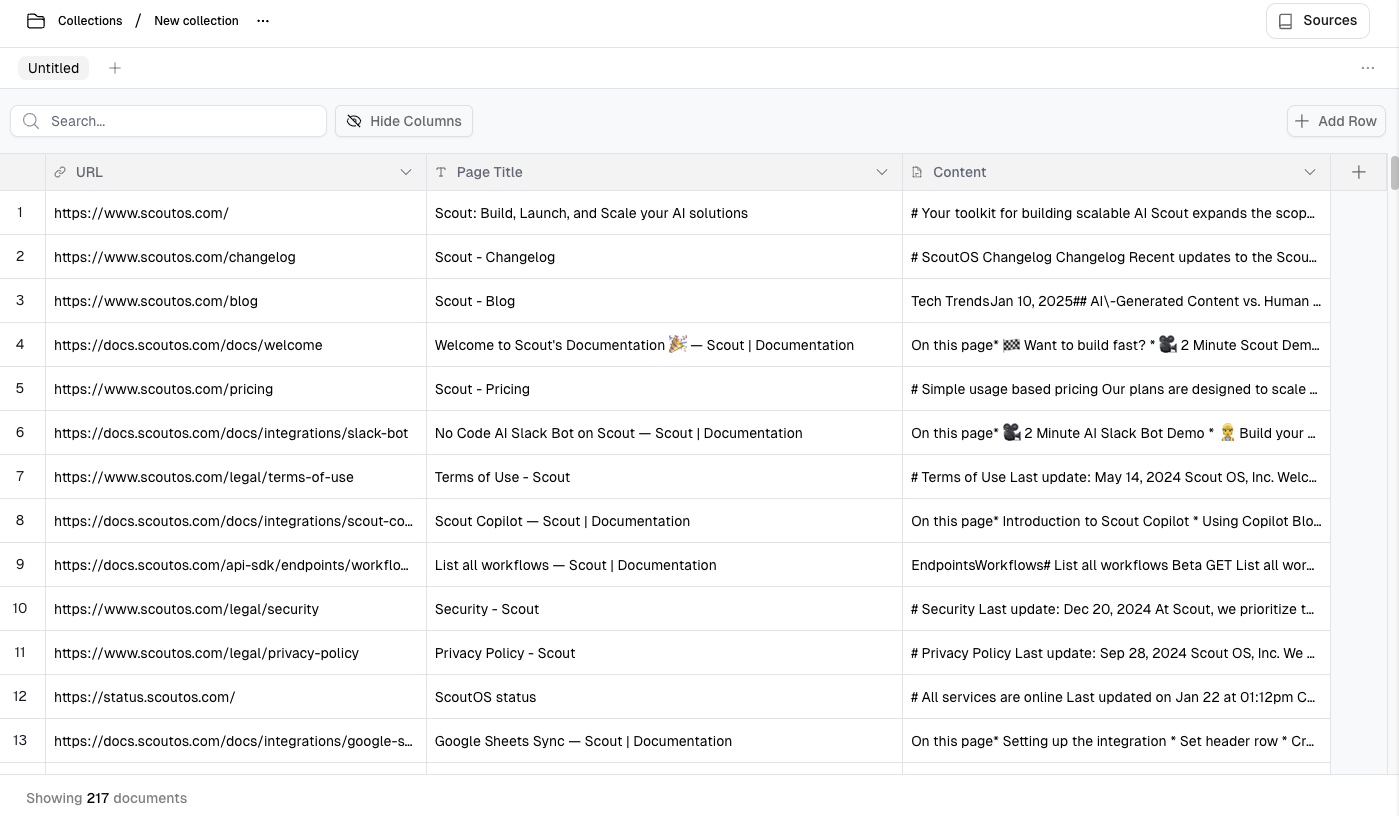
Scraping a Website
Scout provides the ability to setup custom web scrapes sources to populate the tables in your Scout collections with documents. Before getting started created a web scraping source, ensure you’ve created a collection.
There are three different web scraping options: you can enter a URL for scraping a single web page, multiple pages via a sitemap, or an entire site (all URLs) using our crawler.
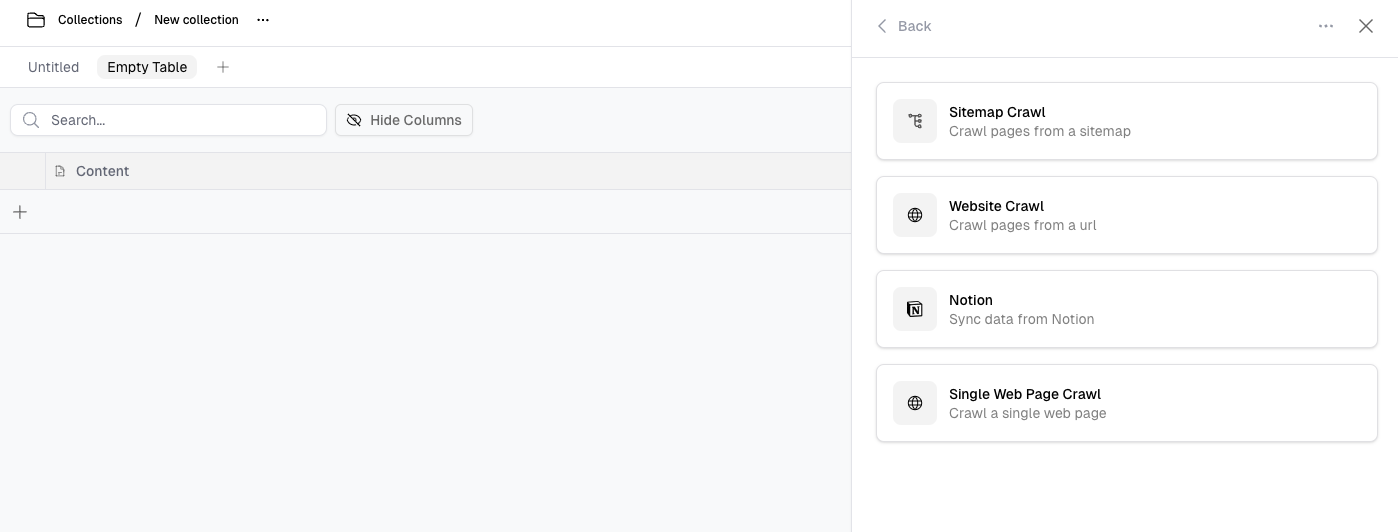
Types of Web Scrapes
Single Web Page
Enter the URL of the single web page you wish to scrape. This will target and extract content from the specific page.
Website Crawl (Multiple Pages)
Initiate a full crawl of a website, scraping multiple linked pages. This option scrapes content from all available pages across the domain.
Sitemap
Provide a sitemap URL. The sitemap will be used to locate and scrape specific pages from the website, as indicated by the sitemap structure.
Configuring Web Scrapes
There are several inputs and settings to give you full control and customization over the scraping process:
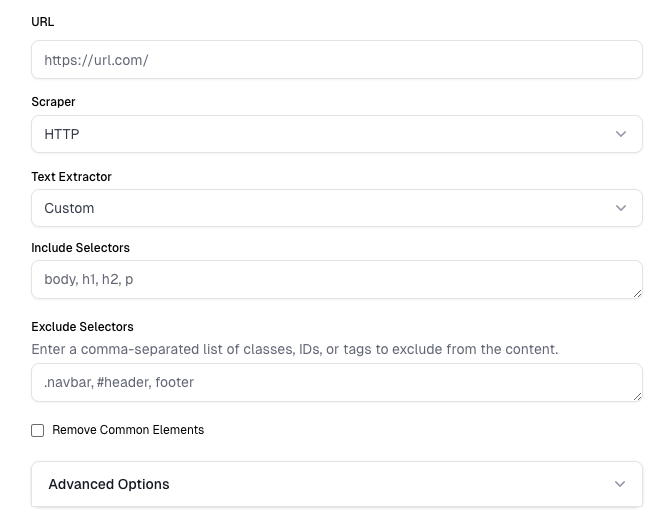
Settings
The full URL of the page, domain, or sitemap you want to scrape.
Additional Settings
Select the scraper technology. Available options are:
- Http - Faster, but may not mix well with heavily client-side rendered sites.
- Playwright - Heavier and slower, but renders dynamic content, which works well with heavily client-side rendered sites.
Defines how text is extracted from the page. Options include:
- Readability - Scout’s smart scraping logic to include relevant components.
- Trafilatura - A Python package and command-line tool used to gather text on the web.
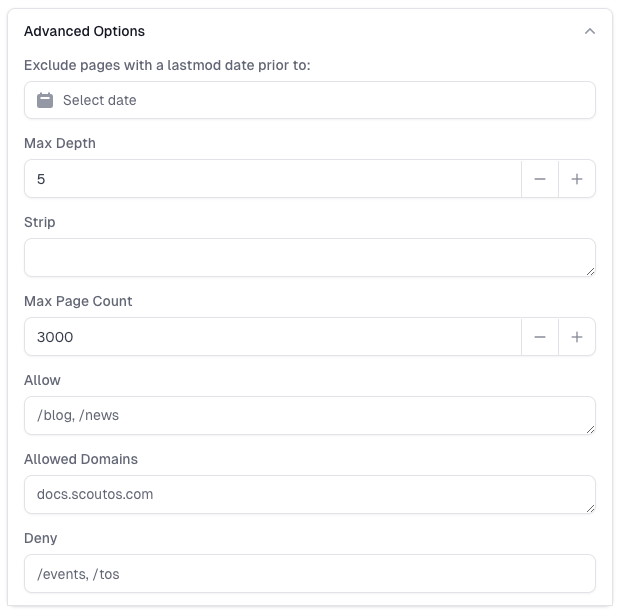
Comma-separated list of URL patterns to include. Only URLs matching these patterns will be crawled.
Comma-separated list of URL patterns to exclude. URLs matching these patterns will be skipped.
Comma-separated list of regex patterns to exclude. URLs matching any of these patterns will be skipped. For example: “/private/, login.html$’ will skip URLs containing ‘/private/’ and ending with ‘login.html’
Comma-separated list of html tags to strip from the content.
Removes query parameters, fragments, or trailing slashes, to simplify or standardize urls.
Comma-separated list of domains to include. Only URLs from these domains will be crawled. Defaults to the domain of the starting URL.
Sets the maximum depth for the crawl. This limits how deep the scraper will follow links from the original page.
Defines the maximum number of pages to scrape. Use this to prevent overly large scrapes.
Mapping
Frequency
The full URL of the page, domain, or sitemap you want to scrape.
Advanced Options
Monitoring Web Scrapes
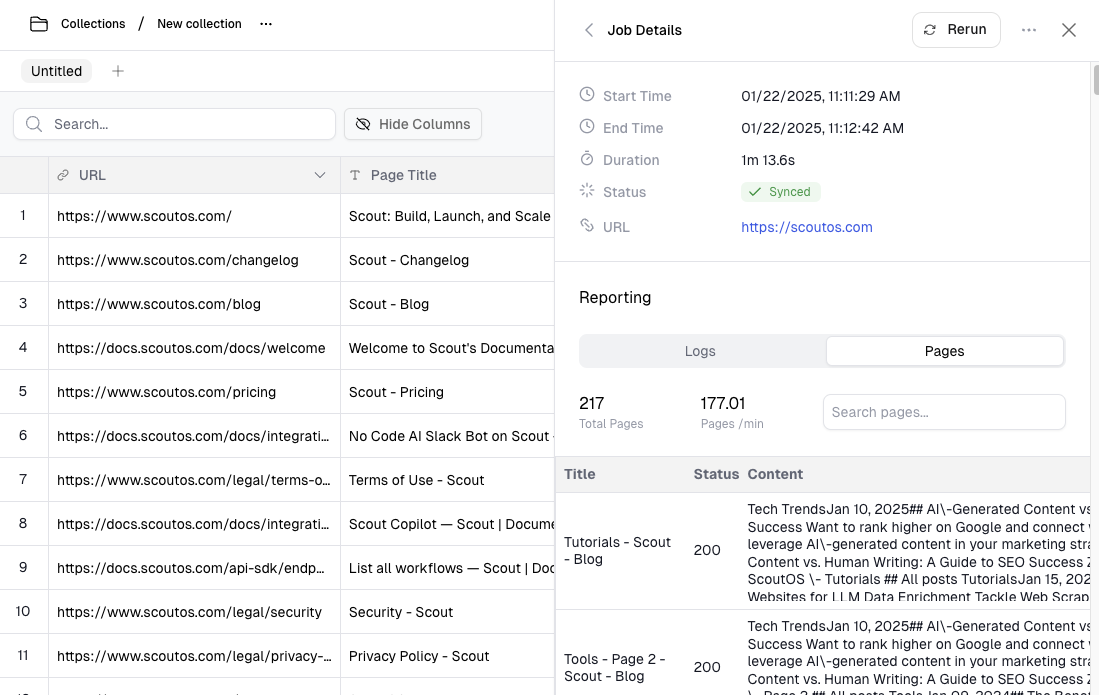
You can monitor the progress of your web scrapes in real-time from the dashboard. Once you click the “Run” button to start a web scrape, you’ll land on a page showing you the progress and status of the process:
Results
Once scraping is complete, the content will be stored as documents in a collection, with each web page being a separate document.